A commercial appeared during Super Bowl 60 for an AI generated predictive health test. The ad included the phase “false positive and false negative results may occur.” My wife, who has a family history of cancer and is interested in the test, asked me, an epidemiologist, what this means. This is my reply to her, and she thought others would benefit from it.
You take a cancer screening test, and you get a result, but it is only a positive or a negative finding — true or false is not mentioned.
Importantly, these screening tests are not considered diagnostic, but, if warranted, they do point to a need for additional testing. The number of false positives and false negatives as well as true positives and true negatives depends on additional diagnostic work-up, the accuracy of the original test, and the prevalence/base rate of the disease in the real world population.
So after receiving a positive or a negative result, the question you should ask is: “What is the chance I will eventually be classified as a false positive or a false negative?”
Here is a little background first.
Say the test was reported to have an “accuracy” of 90%. This is usually based on two classic measures of accuracy. One is a 90% “sensitivity” (termed “recall” by data scientists), based on the number of those who tested positive, divided by the number with the disease. The other is 90% ”specificity“ based on the number of those who tested negative, divided by the number without the disease. For conceptual framework to calculate accuracy metrics see Box 1 below.
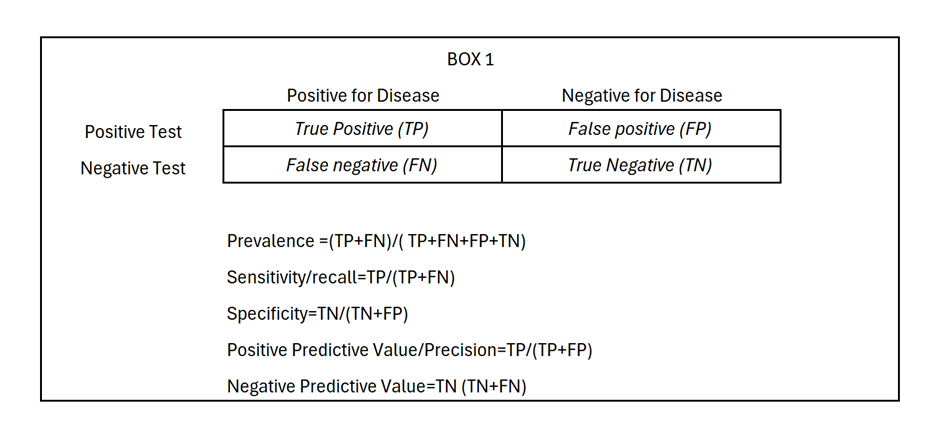
Now I will answer your question based on two examples, shown in this graph:
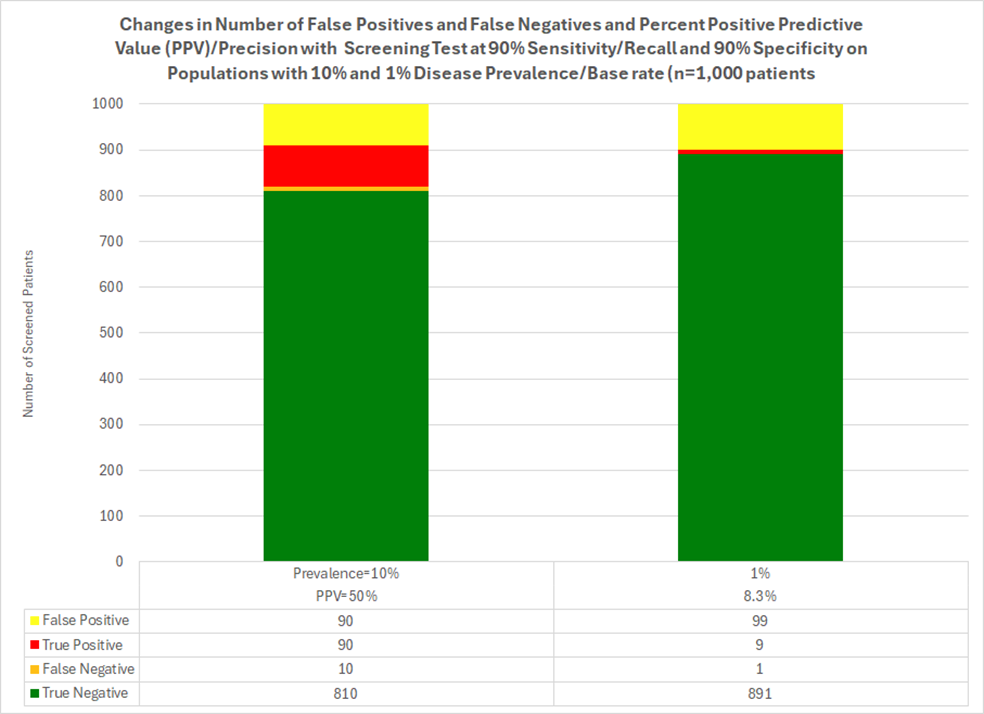
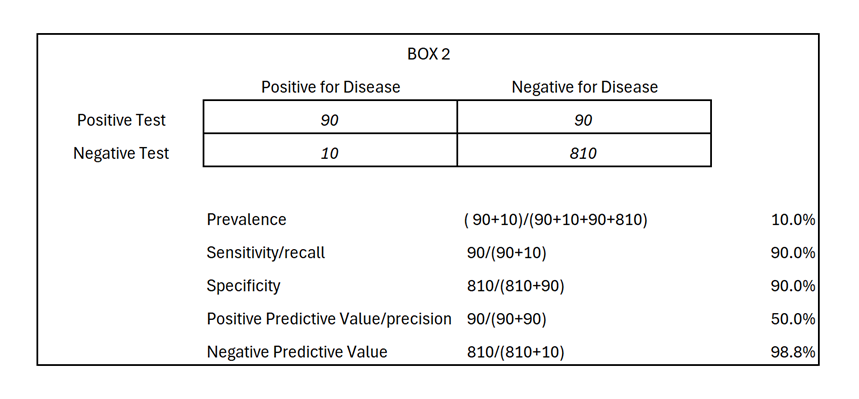
Example #1 (bar on the left, Box 2 below): The prevalence of the disease is 10% in the real world. Without a screening test (and knowing nothing else), the probability you have the disease is 10%. In this scenario with 90% classic accuracy, and in a testing population of n=1,000, 180 test positive. Of those, 90 will be later classified as false positives and 90 as true positives. Thus, the probability you have the condition among all people who test positive is 50% (called Positive Predictive Value or Precision), not 90% as classic accuracy metrics may indicate. Thus, among those who test positive, 50% are true positives. The data also shows us that among all who test negative; these data indicate only 1.2 % are false negatives (the inverse of Negative Predictive Value). To calculate accuracy metrics, see Box 2 below.
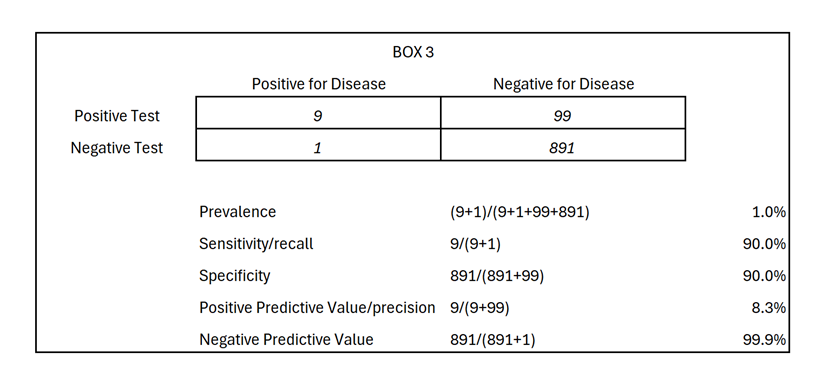
Example #2 (bar on right side, Box 3 below) shows a disease prevalence of only 1% in a population. Without a test, the probability of you having the disease is 1%. With a screening test sharing the same reported 90% classic accuracy as above, and in a testing sample of 1,000, 108 are expected to test positive, with 9 later expected to be classified as true positives and 99 as false positives. Thus, the “positive predictive value” (PPV), i.e. the probability you have the condition given a positive test, is now 8.3%, not 90%. Thus false positives make up 91.6% of those who test positive (the inverse of positive Predictive val87e) while false negatives make up only 0.1% of all those who among all who test negative (the inverse of Negative Predictive Value). To calculate accuracy metrics, see Box 3 below.
So that is a description of the terms false positive and false negative shown in commercials.
Importantly, these results are not only relevant to you, but also our health system, especially when tests are positive. In the first example we saw 180 people who tested positive and that 1 of 2 tested will later be determined to not have the disease. In the second example, 108 people tested positive, and 1 of 10 will be ruled out as not having the disease. These rule-out procedures translate into real costs to the health system; not just your costs and the potential invasive procedure(s) you and each “test positive” patient experiences. There are challenging decisions ahead for patients and health care systems with proliferation of AI-enhanced predictive tests that do not present the chances of being a false positive or false negative. One recommended action is for test manufacturers to be cognizant of not just sensitivity and specificity, but also the prevalence from which is derived the expected predictive value of the findings, whether they be positive or negative, true or false. I hope that future commercials for AI-generated predicted tests reveal detailed information related to real world situations for both consumers/patients, health systems, and public or private policy makers.
Author
Thomas Wilson, PhD, DrPH
Co-Founder & Chief Epidemiology Officer, Trajectory Health AI
RadSite Standards Committee Member
This blog is an expansion of the FDA comment “min-oa91-x27l” submitted 12/1/2025 re: “Docket No. FDA-2025-N-4203 for ‘Measuring and Evaluating Artificial Intelligence-enabled Medical Device Performance in the Real World; Request for Public Comment.’ https://www.regulations.gov/comment/FDA-2025-N-4203-0087
© 2026. Trajectory Health AI, All rights reserved